机器之心专栏
作者:美图影像实验室
近日,美图影像实验室 MTlab 针对低清画质推出高效的人像画质修复算法,轻松解决图片被压缩,亦或是由于夜拍、抓拍或是抖动造成的照片模糊、失焦等问题。
在美图秀秀推出的小程序中,用户只需上传一张老照片,就能使用 AI 还原旧时光,把模糊照片变得更高清。

左:原图,右:修复结果
据了解,美图人像画质修复算法在自研的超清人像生成网络结构 BeautyGAN(Beauty Generative Adversarial Networks)基础上,从美图数以亿计的海量人像数据中学习,使其具备人像画质修复能力,最大程度还原人像原有的脸部信息,重新定义低清画质的宽容度(Portrait Redefinition)。
以下是美图影像实验室 MTlab 对人像画质修复技术的详细解读:
日前,林青霞的一组复古照片在各大社交媒体平台引起了广泛关注与热议,成功将「AI 老照片修复」带入大众视野,也让更多人近距离感受到黑科技的魅力所在。由于早期拍摄设备的配置有限,手机像素比较低,又或是图片经过多次的网络转载和压缩,使得很多老照片画质受损严重,清晰度较差。而随着 AI 的不断发展,尤其是生成技术的发展,使智能修复老照片成为可能。老照片往往承载着许多回忆,甚至是许多人的情感寄托,然而模糊老旧的照片已经无法满足用户日趋严格的审美需求。为了解决这一痛点,美图影像实验室 MTlab 作为美图核心技术研发部门,推出了人像画质修复技术,通过便捷的一键操作就能高清还原老照片中的人像。事实上,除了老照片修复外,还可以修复的场景包括模糊、失焦、压缩等各类低清人像画质照片。
借鉴前沿的深度学习技术,如降噪、增强、超分、强化学习等,在生成网络的基础上,结合大量的对抗式生成网络的前沿技术,进一步加强了美图影像实验室 MTlab 自研的生成网络结构 BeautyGAN 的生成能力。美图凭借自身强大的数据基础,使 BeautyGAN 具备良好的人像修复能力,最大程度还原人像原有的脸部信息。通过网络结构和训练方案的不断优化,提高修复的效率,让用户无需等待,数秒内即可看到人像修复的结果。
人像画质修复完整流程
针对一张待修复的图片,一般分两步来处理。首先利用人脸点抠取脸部,对脸部做修复,使其变清晰;其次对全图进行去彩噪、去噪、去马赛克、去 jpeg 压缩、去模糊、去轻微抖动等画质修复操作,从而达到画质增强的效果。
分辨率比较高的图片在进行全图去噪等操作时,耗时较为严重。为了提高计算效率,美图影像实验室 MTlab 会将待修复图缩小到一定尺度,再进行分块、去噪等修复操作。最后通过 guided-filter 网络结构的画质增强方案恢复为原始分辨率。上述脸部修复和全图修复 (全图修复包括低分辨率修复和高分辨率增强) 并行完成后,将修复后的脸部贴回原图,合成完整的修复图。再利用超分网络,最终使得画质整体变得更加清晰。完整修复图如图 (1) 所示。

图 (1) 画质修复流程
画质增强
前已述及,对于分辨率比较高的图,直接进行去噪等操作存在占用内存或显存高等问题,进而导致计算效率低下。因此,把原图缩小到一定尺度进行低分辨率修复如去噪、去模糊等,将会大幅提升处理效率。在低分辨率修复完成后,借助 Wu 等人 [1] 提出的 DGF 网络结构 (Deep Guided Filtering Network),恢复为原始分辨率或放大为更大分辨率的图。
比如,一张 1280 尺度的图片,缩小到 640 尺度进行去噪、去模糊等修复,得到 640 尺度的修复结果,通过 DGF 网络结构恢复为原始 1280 尺度的分辨率,但实际上若想变为更大尺度 1920 的分辨率,可以把原 1280 尺度的图片先用立方插值放大为 1920(此时放大的结果会变糊),然后利用 640 尺度修复结果加上 DGF 网络结构,可以让 1920 尺度的图片实现去噪、去模糊等修复效果的同时,在 1920 尺度上变得更清晰。即通过低分辨率修复模块和 DGF 网络结构,可以让 1280 尺度的图片放大为 1920 尺度分辨率的图片。
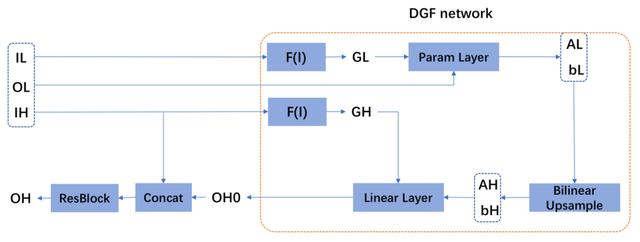
图 (2) DGF 画质增强网络结构及 ResBlock 使用方式
其中,IH 表示高分辨率的原始图片,IL 表示 IH 缩小到一定尺度的低分辨率图片,OL 表示低分辨率图片 IL 修复结果,DGF 网络结构具体参数含义可参考对应文献 [1],OH0 表示 DGF 网络结构输出的结果。
但单纯的 DGF 网络结构做画质增强,会丢失一些细节,因此需要将 DGF 得到的结果 OH0,和原始分辨率的图 IH,通过 concat 的方式,再经过若干个 ResBlock(通道数 4/8 通道即可),从而得到最终画质增强的结果 OH。以下是全图修复 (含脸部修复) 示例:

图 (3) 左:原图,右:修复结果

图 (4) 左:原图,右:修复结果

图 (5) 左:原图,右:修复结果
人脸修复
人脸修复具体包括人脸裁框和脸部生成修复。
1. 人脸裁框
舍弃了以往单纯利用眼睛间距来裁切人脸的方式,而采用最小包围盒矩形框来裁切人脸,具体步骤为:
- (a) 通过目前成熟的基于 CNN 的人脸检测和人脸对齐方法获得图像中的人脸点集 FP,计算其外接矩形,向外拓展得到人脸的裁切矩形。
- (b) 通过人脸的裁切矩形,获得人脸的旋转角度,从原图中裁取摆正后的人脸图像 F。
2.生成网络的设计
由于人脸特有的分布特征,使得其在生成网络结构中能够学习到人脸的共性,由此产生了很多人脸生成的网络结构以及一系列特殊的训练方法,但人脸生成存在五官变形、丢失遮挡 (如手、刘海等) 信息等,使得 DL 生成的人脸和真实人脸存在较大差距,肉眼可见是假脸。但 StyleGAN[2] 的出现解决了这个问题,能够生成一张逼真的人脸,肉眼看不出和真实人脸的差别。其借用图像风格迁移,让生成式网络能够生成一张逼真的人脸。但其仅仅只是生成一张随机的逼真人脸,并不能直接实现一对一的脸部修复,于是需要为其设计 encoder-decoder 的网络形式。同时为了复用 encoder 的 featuremap,保留脸部的五官特征,避免发生变形,需要将其和 decoder 对应大小的 featuremap 连接起来。区别于以往采用加的连接形式,改成 concat 的方式,可保留 encoder 结构的部分 featuremap,避免脸部严重变形或者丢失脸部遮挡 (如手、刘海等) 的信息。具体的网络结构如下图所示:
输入一张大小为 sxs 的图,经过五次下采样,得到一张大小 s32xs32 的 featuremap,再经 5 次上采样,修复生成一张大小为 sxs 的修复脸部图。

图 (6) 人脸修复基本网络
3.构造生成器
为加强 BeautyGAN 的生成能力,借助 StyleGAN 的训练方式,对于生成网络,我们首先训练 decoder 的生成能力,即输入一个大小为 s32xs32 的随机向量,通过逐层的上采样加上 concat 的随机向量,最终生成一张 sxs 大小的人脸,保证生成的人脸看不出真假。以往一些生成网络获得的人脸往往跟真实人脸有差距,一看就是假脸,但结合 StyleGAN 的训练方式,可以让生成网络得到的人脸逼近真实的人脸,肉眼几乎看不出差别。

图 (7) decoder 网络训练结构
对上述 decoder 网络结构作生成器 (generator),加上判别器 (discriminator) 构建 GAN 网络结构,即美图影像实验室 MTlab 改进研发的 gan 网络结构——BeautyGAN。其中,concat 处每次迭代时都生成一个跟相应层 featuremap 大小一致的随机向量,提高 decoder 的生成能力。
当 decoder 结构训练稳定具备生成人脸的能力后,和 encoder 结构合并,进行整个网络结构的训练,让 encoder 部分的学习率高于 decoder 部分的学习率,同时控制好判别器的学习率。以下是部分修复示例:

图 (8) 左:原图,右:修复结果

图 (9) 左:原图,右:修复结果
结语
随着拍照场景需求的日渐多样化,如夜拍(模糊、噪点多)、抓拍(曝光时间短,画质差)等,用户对于画质修复的要求也越来越高。为了满足用户丰富的场景使用需求,美图影像实验室 MTlab 研发了人像画质修复的深度学习算法,帮助用户修复低清画质的清晰度,解决不同场景对于画质清晰度的拍照需求。目前,该技术已成功应用在美图秀秀中。当然,目前的生成网络还存在一定的问题,MTlab 研发人员未来将致力于研发更加有效的训练方法,充分发挥其在图像修复上的技术优势,攻克技术难点,提高人像处理能力,为用户提供更好的拍照体验。
参考文献:[1] H. Wu, S. Zheng, J. Zhang, and K, Huang. Fast End-to-End Trainable Guided Filter. CVPR, 2018.[2] T. Karras, S. Laine, and T. Aila. A Style-Based Generator Architecture for Generative Adversarial Networks. CVPR, 2019








